The Social Media Platform #
Social media platforms are websites and mobile apps that enable users to create and share content or participate in social networking. Examples of social media platforms include Facebook, Twitter, Instagram, LinkedIn, and Reddit. These platforms allow users to connect with others who share similar interests, to share their thoughts and experiences, and to access a wide range of information and news. Some social media platforms focus on specific topics or interests, while others are more general in nature. Many people use social media platforms to stay in touch with friends and family, to discover new information and ideas, and to share their opinions and experiences with others.
There are many different types of social media platforms, including social networks, forums, microblogs, photo and video sharing sites, and more. Some of the most popular examples of social media platforms include Facebook, Twitter, Instagram, and LinkedIn. These sites allow users to create profiles, share information and content, and interact with other users through comments, likes, and other forms of engagement. Other types include messaging and communication apps, such as WhatsApp and Slack, and gaming and entertainment platforms, such as Twitch and Reddit.

Fig.2: The many different types of social media (source: Brian Solis and JESS3 1)
Regardless of the type, the main goal from the platform’s perspective is gain value (e.g., maximize profits by expanding the network or increasing user interactions). The exact strategy may differ depending on the platform. For Wikipedia, for example, content is of central importance. A study revieals that new content leads to significant, substantial, and long-term increases in both content consumption and subsequent contributions2.
Both from a research and a practical perspective, the interaction of different platforms is also interesting. For example, there is a positive cross-platform spillover effect of content virality such that cross-platform posted content gains greater virality3.
Recommender Systems #
A recommender system, also known as a recommendation engine, is a software tool that uses algorithms to predict a user’s interests4. These recommendations can be based on a variety of factors, such as the user’s previous interactions with the system, the behavior of similar users, and the overall popularity of different items. Recommender systems are commonly used in online platforms such as e-commerce websites, streaming services, and social media to help users discover new products, videos, articles, or other content that they might be interested in. The goal of a recommender system is to improve the user’s experience by providing more relevant and personalized recommendations.
There are many different types of recommender systems, all of which have their advantages and disadvantages. The choice of system depends on many factors and not only helps determine the success of the platform, but can also influence user behavior and concentration of interest and consumption5. For example, a switch from a content-based to a social folter algorithm caused an increase of the creation of social ties but also decreased question ansering contribution in a Q&A community6.
Although the specific implementation details are often treated as trade secrets, most companies like TikTok7, Twitter8, Instagram9, or Netflix10 offer insights into the recommender systems they use. In most cases, these are hybrid systems that draw on a plethora of data.

Content-based filtering #
Content-based filtering is a method of recommending items to users based on their preferences and interests. It works by using algorithms to analyze the content of items (such as books, movies, or articles) and match them to a user’s previous choices or preferences. For example, if a user has previously rated a number of romantic comedy movies highly, a content-based filtering system might recommend other romantic comedies to them. Content-based filtering is one of the main techniques used by recommender systems to provide personalized recommendations to users. It is often used in combination with other methods, such as collaborative filtering, which takes into account the preferences of other users.
Collaborative filtering #
Collaborative filtering is a method of recommending items to users based on the preferences and interests of other users. There are two main types of collaborative filtering: item-based and user-based.
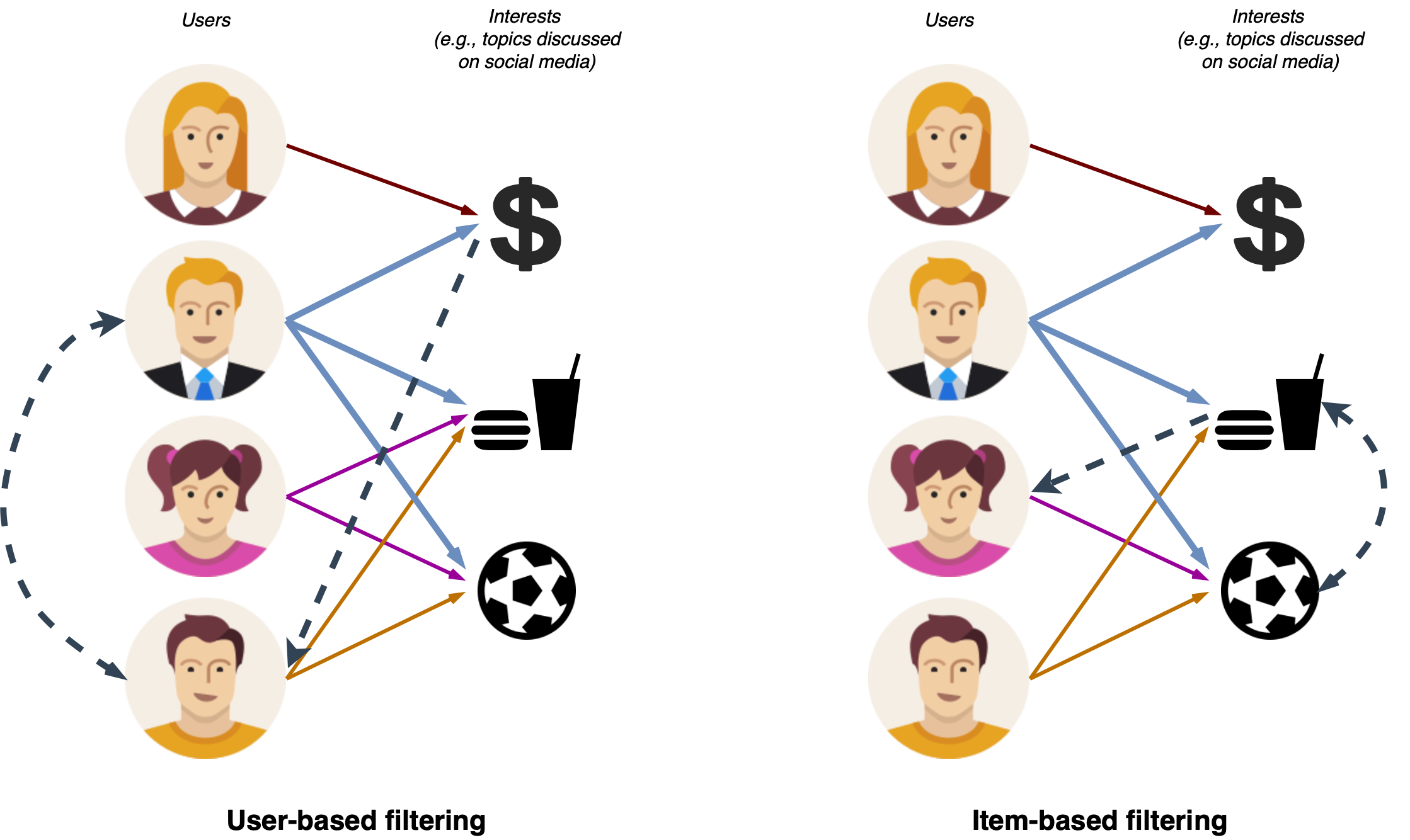
Both item-based and user-based collaborative filtering can be useful for providing personalized recommendations to users. Which one is more effective can depend on the specific characteristics of the data and the goals of the recommendation system.
Implicit and explicit feedback are two types of information that can be used by collobrative filtering algorithms to make personalized recommendations to users4.
Implicit feedback is information that is inferred from a user’s behavior, such as their browsing history, the items they have clicked on, or the amount of time they have spent viewing a particular item. This type of feedback does not require the user to actively provide ratings or preferences, but it can still be useful for making recommendations. Explicit feedback, on the other hand, is information that is provided directly by the user, such as ratings, reviews, or tags that they have assigned to different items. This type of feedback is more direct and specific, but it also requires the user to take an active role in providing it.
Both implicit and explicit feedback can be useful for recommendation systems, and many systems use a combination of the two. Implicit feedback can provide a more comprehensive view of a user’s interests and preferences, while explicit feedback can provide more detailed and specific information.
Social filtering recommmender system #
A social filtering recommender system is a type of recommendation system that uses the opinions and preferences of a user’s social network to make recommendations. This means that the recommendations are not just based on the user’s own past behavior and preferences, but also on the behavior and preferences of their friends, family, and other contacts6. For example, if a user’s friend has rated a particular movie highly, a social filtering recommender system might recommend that movie to the user, even if they have not yet rated it themselves. Social filtering recommender systems can be useful for providing more diverse and potentially more accurate recommendations, as they take into account the collective wisdom of a user’s social network. However, they can also be subject to biases and misinformation if the user’s social network is not diverse or well-informed.
Reciprocal Recommender Systems #
Reciprocal recommender systems are a type of recommendation system that takes into account the reciprocity of interactions between users. This means that the recommendations are not just based on the preferences and interests of individual users, but also on the interactions between those users. For example, if two users have both rated a particular movie highly and have also communicated with each other about the movie, a reciprocal recommender system might recommend that movie to other users who have interacted with one or both of those users. Reciprocal recommender systems can be useful for providing recommendations that take into account the social context of user interactions, and for highlighting content that has been endorsed by multiple users. However, they can also be subject to biases and misinformation if the interactions between users are not diverse or well-informed.
**In-class task**: SurveyIn this survey you are to rate artists. This explicit feedback will be analyzed afterwards. Add a new row to the following Google Docs spreadsheet. The first column should contain your nickname. If privacy is important to you, use a name that cannot be associated with your person. After that, give each artist a rating: - -1: don't like - 0: neutral - 1: like Link: **[https://short.wu.ac.at/sma-survey](https://short.wu.ac.at/sma-survey)**
Content filters #
A content filter is a software tool that uses algorithms to screen out unwanted or inappropriate content from a user’s online experience. Recommender systems and content filters are similar in that they both aim to provide personalized recommendations to users based on their interests and preferences. However, there are some key differences between the two.
Recommender engines make predictions about what a user might be interested in based on their past behavior and the behavior of similar users. They are typically used to recommend products, videos, articles, or other content that a user might enjoy. Content filters, on the other hand, are used to filter out content that a user might not want to see based on their preferences or settings. For example, a content filter might be used to hide explicit or offensive content from a user’s social media feed, or to block certain websites from appearing in their search results.
In general, recommender systems are focused on providing personalized recommendations to users, while content filters are focused on removing unwanted or inappropriate content. Both can be useful tools for improving the user experience on online platforms.
**In-class task**: Experience online personalization If you have mobile devices (laptops or alternatively smartphones) with you, pick them up now. Go to the following websites and services and compare what you see with your colleagues. - [google.com](https://google.com); search for "LaTex" (or [LaTex wallpaper](https://ctan.org/pkg/wallpaper)) - Open your spotify app (if you are customer) and go to ["Your Daily Mix"](https://newsroom.spotify.com/2018-05-18/how-your-daily-mix-just-gets-you/)
In its most general definition, a content filter is a software that blocks and restricts internet users’ content under normal conditions. Individuals, companies, or countries can use content filtering. For example, a corporation can limit social media content not to distract employees during working hours or parents can use web content filtering to keep inappropriate content away from their children.
Content filtering in a social media context is a little bit different concept than the first definition. It’s about blocking or restricting the content and prioritizing and sorting posts in a user’s timeline. While many social networks originally ordered the news feeds chronologically, the order is now often based on machine learning. Consequently, it is no longer your friends who determine what you see but the platforms. Most platforms do not want to filter explicitly, but talk about sorting in the sense of the customer - after all, content that is more relevant to the customer is displayed more prominently. To express that the focus here is on sorting, the term “ranking” is usually used, i.e. the arrangement of content instead of filtering. However, analogous to a Google search where only the first entries are considered, content ranked last will also receive little to no attention. Examples, of ranking algorithmn on social media platforms comprise:
- Instagram ranks the content not not chronological anymore.
- The posts on your Facebook timeline are not listed chronologically either.
- Twitter’s Recommendation system
The definition of “relevance” or the objective that these ranking-algorithms pursue is not always clear.
**Example:** With the volume of knowledge accessible on the internet, it is almost impossible to find the information people need without some help sorting out this material. Google ranking systems are built to do precisely this: filter hundreds of billions of web pages to immediately identify the most essential and valuable links. Google is ranking the results based on many variables including the query, properties of the pages and the user.
Filter Bubble #
Curation algorithms (i.e., recommender systems) are often accused of polarizing user consumption6. A filter bubble is a state of personalization in which an individual’s web content is largely tailored to their interests and preferences, as determined by these algorithms. The term was coined by internet activist Eli Pariser, who argued that the use of personalization algorithms by major internet companies could lead to the creation of “filter bubbles” that limit the flow of diverse ideas and perspectives (similar to “echo chambers” in media). This can lead to a lack of exposure to diverse viewpoints, as the individual is only presented with information that aligns with their pre-existing beliefs and opinions. Moreover, curation algorithms impact the number of people user follow and the quality of content generated on the network11. A study on Facebook found that only one fourth of our online friends have contrasting views12.
Filter bubbles have been criticized for potentially contributing to the spread of misinformation and the reinforcement of echo chambers. Although, some filter bubbles may limit diversity, others are the result of user choice13. Nevertheless, mass media should provide their consumers with balanced news, enable the citizens to be well informed, and show different perspectives on all relevant topics1. This is generally seen as a critical function of news quality in every democratic state. However, it is clear that this is not possible anymore if everybody in society is in a different filter bubble and cannot get information from different perspectives. In the end, filter bubbles may lead to a reduced diversity resulting in partial information blindness.
Although, there is only minimal empirical evidence of the existence or effects of filter bubbles, it is a very much discussed topic14.
Challenges #
The biggest challenges include the veracity of users and the content.
Political bias on social media #
Social media platforms like Twitter (more-or-less) carefully position themselves to users, customers, advertisers, and policymakers by making strategic statements about what they do and don’t do15. The term “platform,” in particular, reveals the contours of this discursive work and is used in both their populist appeals and their marketing pitches. As these providers become curators of public discourse, we need to examine their independence, non-partisanship, and freedom of speech. In particular, since tensions may exist in serving all these constituencies1617.
**Example:** As the recent past has shown with the example of Twitter, the situation and orientation of a platform can also change quickly. Since Elon Musk took over Twitter, the network's political focus has changed dramatically.
**In-class task:** Reading exercise Please read the article [General Mills, Audi and Pfizer Join Growing List of Companies Pausing Twitter Ads](https://short.wu.ac.at/pausing-ads-on-twitter). Afterwards we'll discuss the following questions in-class: - What are potential reasons for these decisions? - What is the role of Elon Musk and especially his other endeavors? Link: **https://short.wu.ac.at/pausing-ads-on-twitter**
Identity, Anonymity & Authenticity of Users #
Not every user profile corresponds to a real person. In some cases, online profiles are shared, several profiles are used by one person, or they are not real people at all. This increasingly leads to discussions around false news or biased engagement online. The problem affects both users and companies. Since, it is the platform that can do something about it, we will look at it from a platform perspective.
Social media platforms like Instagram and Facebook generate extremely high revenues through companies that advertise products and services online. While it doesn’t matter if real users see those “Ads” in terms of revenue in the first place, companies might start to be concerned about their actual reach and therefore use this service less, which negatively affects the platform18.
While there is a right to pseudonymity in the U.S., in the German-speaking world a obligation to use a “real name” (Klarnamenpflicht) is becoming an increasingly frequent topic of discussion 19 20. However, disclosing user information may be used to threaten them both online and offline21. A middle ground could take place through verification by the platform. In this way, a person’s real name would not be publicly visible, but the platform would verify that it is a real person. Such an approach is partly implemented or contemplated by platforms (e.g. Twitter). Moreover, studies have shown that such verification by the platform changes user behavior and that the verified person has a positive effect on the engagement received22. In addition, a platform-side verification of users can also be monitarized (e.g., Twitter Blue).
Social (ro)bots & Fake accounts #
A (ro)bot is an agent that acts mostly autonomously, often build for a highly-specific task in mind. Consequently, a social bot is an agent that acts on social media platforms, often with the task of influencing the course of discussion and/or the opinions of its readers. It is also often known as fake accounts or fake profiles. However, fake profiles do not always act autonomously and may still contain real material. There are several reasons why such profiles are created: exposure of detailed personal information of users, to review and rate a product to help a business grow, reach and influence potential customers, fake traffic for blog websites, or also spamming other users, to name a few examples18.
It is essential to understand that those profiles affect not only the platforms users, but also the evaluation of the whole platform. For example, the presence of bots on Twitter has become recurrent. This issue was named by Elon Musk as a reason for Twitter’s incorrect rating23.
Before the platform removes those fake profiles, they need to be detected first. For this purpose exist several approaches. Some are based on the individual profiles, others on the interactions between profiles. However, Facebook claims that the best way to get rid of the fake profile problem is to prevent their creation24. They measure signals that indicate mass account creation and block IP addresses to ensure no fake profiles are created. If someone still manages to create a fake profile, Facebook often manages to detect them by exhibiting signs of malicious activity or other users reporting the profile.
Fake Content #
A lot of content, especially product and company reviews online, are not based on opinions of individuals, but are written on commission. Especially for online reviews, there are dedicated platforms where companies can commission them. Even companies with many reviews and high average ratings by fake reviews. It brings a significant but short-term increase in average rating and number of reviews; after firms stop buying fake reviews, their average ratings fall and the share of one-star reviews increases significantly25.
False News #
A lie can travel half way around the world while the truth is putting on its shoes
Mark Twain
Nowadays, fake news can be spread more quickly than in former times, illustrated in newspapers, and streamed via television or radio. Fake news has a significant impact on our society. People spend more time online reading news, posts about recent topics, listening to podcasts, or watching YouTube videos. The media that are often used to spread unreliable information are social media platforms that allow people or companies to spread fake news faster than before.
A study based on 14 million Twitter messages with 400,000 claims found evidence of how bots played an important role in spreading fake news during the American election26. However, the motives are not always clear and manifold. Some do it to spread their world views, while trolls do it for the fun of it. Often, political, financial, and social factors are named as the main motives27.
Of course, there needs to be a receptive audience that likes, shares, and comments on those ‘Fake News’ posts on Facebook or other social media platforms. Therefore, these website owners know precisely how to direct fake news to a specific group of people using social media analytics and microtargeting tools. Notably, humans are more likely to be responsible for the spread of fake news than bots. Researchers at the MIT were interested in how and why true and false news stories spread differently 28. They find evidence that false news spread significantly farther, faster, deeper, and more broadly than the truth in all categories of information. Consequently, bots or other automated processes are not the main culprits in spreading falsity.
People must come up with some solution to tackle the problem of fake news. Social media giants must become more open and collaborate to stop the spread of misinformation. Additionally, teaching people to spot fake news themselves is even more critical29.
“[E]arly detection is especially important for fake news as the more fake news spreads,
the more likely for people to trust it. Meanwhile, it is difficult to correct users’
perceptions after fake news has gained their trust”.Zhou, 2018, p.31
The last crucial point is to account that the law, government, and political actors and institutions should be aware of their impact on fake news. Moreover, if they stand behind the generation of false information because of profit incentives, individuals or organizations have greater motivation and capability to spread fake news29.
Even the most significant player in the Social Media Platforms like Facebook and Twitter just started lately with their regulations against fake news. It is not clear that every user can identify and differentiate true from false information, mainly if it includes some facts30. This opened the conspiracy theories to a whole new audience where the platform itself never did anything against the spread of false information. This can also get dangerous when people take real-life actions based on their knowledge gained on incorrect information.
Finally, recent research relativates the problem. In particular, news consumpation of any sort is heavily outweighted by other forms and fake news consumption comprises only 0.15% of Americans’ daily media diet31.
## Practical assignment II SQL-prerequisites: [Aggregate](https://duckdb.org/docs/sql/aggregates) functions, [GROUP BY](https://duckdb.org/docs/sql/query_syntax/groupby)-Clause & [HAVING](https://duckdb.org/docs/sql/query_syntax/having)-Clause In line with the first assignment, the following questions all refer to a table called *youtube_tweets* (please import it as we did in the first session). This table contains Tweets that contained a YouTube link and were posted in Germany or German in December 2022. Besides the text, the table comprises information about the author and the tweet. Use the [DuckDB Shell](https://shell.duckdb.org) to answer the following questions: - How many observations (i.e., rows) does the table have? - How many tweets have more than 10.000 likes (_like_count_)? - What is the minimum, average and maximum number of followers (_followers_count_)? Please use one query to answer it! - Group the table by the language (_lang_) and return for each language the number of tweets; sort the result descending by the number of tweets. What is the language with the third-most tweets? Check the ISO 639-2 and ISO 639-3 standards for further information. - Return two columns, the username and the average number of replies (_reply_count_) of all users (_username_) with more than 500 tweets (per user). Which user tweeted the most? Please submit your SQL-query as well as a short and precise textual answer via Learn@WU.
References & further reading #
- Slides: The Platform
- Pariser, E. (2011). The filter bubble: How the new personalized web is changing what we read and how we think. Penguin.
- Gillespie, T. (2018). Custodians of the Internet: Platforms, content moderation, and the hidden decisions that shape social media. Yale University Press.
- Netflix released a film called The Social Dilemma. It critically examines content filtering and the power of social media platforms that comes with it.
De Corniere, A., & Sarvary, M. (2022). Social media and news: Content bundling and news quality. Management Science. ↩︎ ↩︎
Zhu, K., Walker, D., & Muchnik, L. (2020). Content growth and attention contagion in information networks: Addressing information poverty on Wikipedia. Information Systems Research, 31(2), 491-509. ↩︎
Krijestorac, H., Garg, R., & Mahajan, V. (2020). Cross-platform spillover effects in consumption of viral content: A quasi-experimental analysis using synthetic controls. Information Systems Research, 31(2), 449-472. ↩︎
Resnick, P., & Varian, H. R. (1997). Recommender systems. Communications of the ACM, 40(3), 56-58. ↩︎ ↩︎
Fleder, D., & Hosanagar, K. (2009). Blockbuster culture’s next rise or fall: The impact of recommender systems on sales diversity. Management Science, 55(5), 697-712. ↩︎
Liu, J., & Cong, Z. (2022). EXPRESS: The Daily Me versus the Daily Others: How Do Recommendation Algorithms Change User Interests? Evidence from a Knowledge-Sharing Platform. Journal of Marketing Research, 00222437221134237. ↩︎ ↩︎ ↩︎
https://newsroom.tiktok.com/en-us/how-tiktok-recommends-videos-for-you ↩︎
https://blog.twitter.com/engineering/en_us/topics/insights/2020/what_twitter_learned_from_recsys2020 ↩︎
https://ai.facebook.com/blog/powered-by-ai-instagrams-explore-recommender-system/ ↩︎
https://research.netflix.com/research-area/recommendations ↩︎
Berman, R., & Katona, Z. (2020). Curation algorithms and filter bubbles in social networks. Marketing Science, 39(2), 296-316. ↩︎
Bakshy, E., Messing, S., & Adamic, L. A. (2015). Exposure to ideologically diverse news and opinion on Facebook. Science, 348(6239), 1130-1132. ↩︎
http://techland.time.com/2011/05/16/5-questions-with-eli-pariser-author-of-the-filter-bubble/ ↩︎
Groshek, J., & Koc-Michalska, K. (2017). Helping populism win? Social media use, filter bubbles, and support for populist presidential candidates in the 2016 US election campaign. Information, Communication & Society, 20(9), 1389-1407. ↩︎
Gillespie, T. (2010). The politics of ‘platforms’. New media & society, 12(3), 347-364. ↩︎
https://edition.cnn.com/2020/05/27/tech/yoel-roth-twitter-fact-check/index.html ↩︎
https://www.pewresearch.org/fact-tank/2021/04/07/partisan-differences-in-social-media-use-show-up-for-some-platforms-but-not-facebook/ ↩︎
Krombholz, K., Merkl, D., & Weippl, E. (2012). Fake identities in social media: A case study on the sustainability of the Facebook business model. Journal of Service Science Research, 4(2), 175-212. ↩︎ ↩︎
https://netzpolitik.org/2019/digitales-vermummungsverbot-oesterreich-will-klarnamen-und-wohnsitz-von-forennutzern/#netzpolitik-pw ↩︎
Fire, M., Goldschmidt, R., & Elovici, Y. (2014). Online social networks: threats and solutions. IEEE Communications Surveys & Tutorials, 16(4), 2019-2036. ↩︎
Taylor, S. J., Muchnik, L., Kumar, M., & Aral, S. (2022). Identity effects in social media. Nature Human Behaviour, 1-11. ↩︎
He, S., Hollenbeck, B., & Proserpio, D. (2022). The market for fake reviews. Marketing Science. ↩︎
Shao, C., Ciampaglia, G. L., Varol, O., Flammini, A., & Menczer, F. (2017). The spread of fake news by social bots. arXiv preprint arXiv:1707.07592, 96, 104. ↩︎
Kalsnes, B., & Larsson, A. O. (2018). Understanding news sharing across social media: Detailing distribution on Facebook and Twitter. Journalism studies, 19(11), 1669-1688. ↩︎
Vosoughi, S., Roy, D., & Aral, S. (2018). The spread of true and false news online. Science, 359(6380), 1146-1151. ↩︎
Zhou, X., & Zafarani, R. (2018). Fake news: A survey of research, detection methods, and opportunities. arXiv preprint arXiv:1812.00315, 2. ↩︎ ↩︎
Lazer, D. M., Baum, M. A., Benkler, Y., Berinsky, A. J., Greenhill, K. M., Menczer, F., … & Zittrain, J. L. (2018). The science of fake news. Science, 359(6380), 1094-1096. ↩︎
Allen, J., Howland, B., Mobius, M., Rothschild, D., & Watts, D. J. (2020). Evaluating the fake news problem at the scale of the information ecosystem. Science Advances, 6(14), eaay3539. ↩︎